Introduction to processes
CS 273 (OS), Fall 2020
Basic notions
A process is an execution of a program
- The same program may be executed by multiple processes
Creation of processes
- Linux:
fork(), clones a process;
execve()changes program being executed by calling process - Windows:
CreateProcess, creates a new process and loads its program.
10 parameters, many involving options
~100 Win32 functions related to process management, synchronization, etc. - Windows approach is typical of non-Linux operating systems
- Linux:
Terminating processes
- Normal vs. error exits (voluntary);
fatal error (e.g., segmentation fault) vs. killed by another process (involuntary)
- Normal vs. error exits (voluntary);
Process hierarchies
- Linux: Parent/child relationship (from
fork()) defines a tree-like hierarchy; a child always knows its parent. - Windows: No fixed process hierarchy. Parents can know their children (through handle token), but may pass this access to other processes.
- Linux process groups are typically all the descendant
processes for a parent;
setpgrp()allows limited rearrangement of process groups (e.g., a shell may place all processes in a pipeline in a particular process group).
Processes may only send signals to members of the same process group, or to that process group as a whole. - In Linux, the tree of parents and children has one root, with pid
0, which is part of the boot image (never
fork()d orexecve()d). Process 0 creates theinitprocess, which is the parent of all other processes; itfork/execves agettyprocess for each terminal (e.g., prompts forlogin:), which childexecvesloginto receive and validate passwords, thenexecves the user's login shell to begin a session (fig 10-11, p.757).
- Linux: Parent/child relationship (from
Process states
- A process state is maintained by OS for each process.
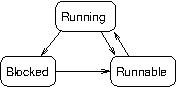
There is only one running process per CPU.
A runnable process is ready to run (at time determined by scheduler).
When a process can run no further (e.g., awaiting I/O), it becomes blocked. - A deadlocked process is a member of a set of blocked
processes, each of which awaits event(s) that can only be generated by
other processes in that set. None of the deadlocked processes can
ever run again, unless someone intervenes somehow (e.g., killing
selected processes and generating some events).
Deadlock is not a process state, since OS (usually) is unaware of it.
- A process state is maintained by OS for each process.
Example data structures and algorithms for processes
Process table, with one process table entry (PTE) per process.
- Contents of a PTE includes information such as the
following:
- process state
- boundaries of memory segments for that process (e.g., program code segment, data segment, stack segment)
- scheduling fields (queue pointers, priority, etc.)
- saved register values for non-running processes (including PC, SP, general purpose registers, etc.)
- array of signal handlers and vector of pending signals
- current working directory, uid, gid
- elapsed CPU time (user time, system time)
In Linux, the process table is a circular linked list of PTEs. Each PTE has the type
task_struct, which consists of hundreds of fields per process, plus additional fields specific to memory management and file systems.Here are some example fields of the Linux
task_struct(in descriptions, "this process" refers to the process for a giventask_structelement in the process table).mmandfs- pointers to memory-management and file-systems data structures for this processstatepid- the process id number for this process.The kernel maintains a hash table to quickly find the
task_structfor a givenpid.Compare to:
getpid()system call; parent's return fromfork()
parent,children,sibling, andgroup_leader- addresses oftask_structentries for processes that have relationships to this process.utimeandstime- counters indicating the amount of time spent by this process executing user code (utime) and kernel code (stime, for system time).Compare to: Linux
timecommand
files- points to a data structurefiles_structthat contains all information about open files related to this process.The file-descriptor table is an array
fdof pointers tofiledata structures. The fieldfdis nested withinfiles_struct.Compare to: In-class discussions of kernel data structure per open file and file-descriptor table
sighand- pointer to asighand_structsignal-handler data structure, which includes an arrayaction[]ofk_sigactiondata structures, one such structure for each signal number.The system call
signal(N, func)assigns the address of a new signal-handler functionfuncto a fieldsa_handlerthat is nested within thek_sigactiondata structure for the given indexN.Compare to:
signal.shdemo
The
final linein definition of thetask_structdata structure (PTE) - total of 627 lines long!
- Contents of a PTE includes information such as the
following:
The interrupt vector contains addresses of interrupt handlers, code to be called when an interrupt occurs. Each CPU can be interrupted separately, so there is one interrupt vector per CPU.
- Shared by all processes
- Recall that an interrupt is a hardware-generated event, e.g., notification that a character has been entered, that a memory address doesn't exist, or that a clock tick has occurred
- Implementation:
irq_desc[],struct irq_desc.
The scheduler is the code within the kernel responsible for determining which process becomes runnable next (implements scheduling algorithm)
In Linux, a function
scheduleselects a next process to run.Some factors in scheduling algorithm:
Time sharing: processes run for segments of time called time slices, and resume where they left off when they start their next time slice.
Priority: each process has an assigned priority p (integer up to 40). During a time slice, a
counterstarts at p and is decremented over time until it reaches 0, at which point that time slice ends.Interactive vs. Batch vs. Real-time classifications have an influence. Interactive processes must be responsive -- short delays to events such as key presses. Batch processes receive lower priority, do not need responsiveness. Real-time processes receive especially quick response time, very low variance (but do not have guaranteed scheduling in Linux).
I/O-bound processes (mostly performing I/O operations) receive high priority, since they already wait long for their I/O operations, and their time slices tend to be short (since those time slices usually end soon, waiting for I/O). Compute-bound processes (rarely performing I/O operations) receive long time slices to reduce overhead due to context switches
General algorithm used by Linux when an interrupt occurs:
- Current values of PC, PSW, etc., stored on interrupt stack, by hardware
- Hardware loads new value for PC from interrupt vector, thus calling interrupt handler
- Interrupt handler first saves other CPU registers (AL)
- Interrupt handler sets up new stack (AL)
- Response to the interrupt (C)
- Scheduler determines next process to run
- Return to AL portion of interrupt handler, which then starts up new process.