{kind=link}
In-class notes for 04/02/2014
CS 121B (CS1), Spring 2014
Quiz today
Submitted questions on assignments and technology
String formatting examples (omit the -->)
def moInterest(princ, rate): return princ*rate/(12*100) moInterest(842.57, 7.8) print("The monthly interest due on a loan with remaining principal") print("${:4.2f} at an annual interest rate of {:3.1f}% is ${:4.2f}".format( 842.57, 7.8, moInterest(842.57, 7.8)))
Upcoming
Submitted questions on readings
Intro to WebMapReduce
Motivation: e.g., photos, Facebook data
Units of quantity:
- K (kilo-), about 1000
- M (mega-), about 1,000,000 (million)
- G (giga-), about 1,000,000,000 (billion)
- ...
Other examples: Google search, email, maps
How can computations be performed with such large data?
WebMapReduce (WMR) is a general-purpose framework for very large-scale computing.
WMR is a simplified interface for software called Hadoop, used by Facebook and other companies for their Data-Intensive Scalable Computing
Map-reduce computing
-
Basic idea of map-reduce computing:
Break data up into labelled pieces (
mapper())Gather and combine pieces with the same label (
reducer())
Example: For computing word frequencies, we
- break up each line
of text into words, and emit a labelled piece (key = word, value =
'1') for each word found, then - gather all the
'1's for each word, and add up those'1's as integers to determine the frequency for that word.
Stages of computation:
mapper stage: start with one line of the original data; produce intermediate key-value pairs.
shuffle stage: organize key-value pairs according to key; transmit across network to a convenient location for next stage.
reducer stage: start with all key-value pairs for a given fixed key; produce result key-value pairs of interest.
A map-reduce implementation (such as
Hadoop, which we use) takes care of details such as splitting the data and shuffling, so a map-reduce programmer needs only provide mapper and reducer algorithms.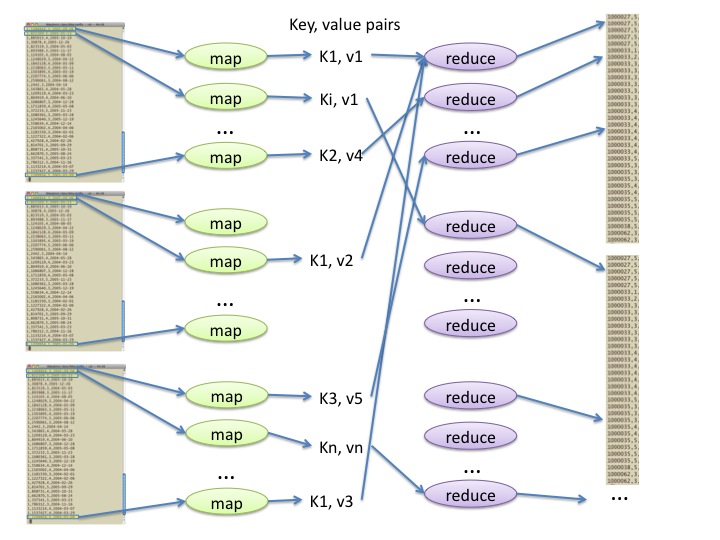
Word counting with WebMapReduce
Exercises
Exercise 1: Use WMR to compute the highest reviewer id in a netflix dataset.
HintsA sample data set:
1,1596531,5,2004-01-23 3,2318004,4,2004-02-05 6,110641,5,2003-12-15 8,1447639,4,2005-03-27 8,2557899,5,2005-04-16 6,52076,4,2004-10-05 1,13651,3,2004-06-16 1,1374216,2,2005-09-23
Spec for mapper:
# IN format # key is a netflix record value is empty string # NOTE: netflix record format is movieID,reviewerID,rating,date # OUT format # key is empty value is a reviewerID
Spec for reducer:
# IN format # key is empty value are reviewerID # NOTE: the values are packed into an interator iter # OUT format # key is maximum reviewer id value is empty
Hints: (a) use
split()with an argument; (b) use an accumulator in reducer to determine the maximum value (since reviewerIDs are non-negative, you can initialize accumulator at -1); (c) use the Test interface to debug.
Exercise 2: Compute the average ratings for all movies
You can use the same data set as above. For that data set, the results should be:
1 3.3333 3 4 6 4.5 8 4.5mapper()specs# IN format # key is a netflix record value is empty string # NOTE: netflix record format is movieID,reviewerID,rating,date # OUT format # key is a movieID value is a rating
reducer()specs# IN format # key is a movieID values are ratings # OUT format # key is a movieID value is the mean movie rating for that movie
Hints: (a) Use two accumulators in reducer, one for sum and one for count, in order to compute the mean
Large netflix data sets on WMR system (cluster paths):
/shared/netflix/test -- all ratings on 100 movies /shared/netflix/all -- all ratings on all movies (don't use in class!)
Note: Don't use Test computation with large data sets. The Test system will cut off the data after a certain number of characters, and it may lead to an incorrectly formatted record at the point of the cut.
< >