Create a directory for your work on this lab.
If you haven't already done so, create a directory
~/PDC for your work in this course. Later in this lab,
we will convert this directory to a git working directory
so you can submit and retrieve your work.
% cd ~
% mkdir PDC
(Don't enter the % sign: it stands for the
csh shell prompt on a CS lab or classroom machine.)Create a directory within ~/PDC for your work on
this lab.
% cd ~/PDC
% mkdir lab1
% cd lab1
Set up passwordless SSH from your account on the link computers
to the cumulus head node, and to the head
node(s) of other cluster(s). (This is a convenience, providing a
secure way to access the clusters without having to enter your
password often.)
Create a directory ~/.ssh on a Link machine, if
you don't already have one.
% mkdir ~/.ssh
% chmod 700 ~/.ssh
% cd ~/.ssh
Don't forget the "dot". Note: The chmod
command changes the Linux protection of that directory so that only
your account (and the root account) can access it.Generate a public key and a private key for authentication.
% ssh-keygen -t rsa -P ""
Copy the public key id_rsa.pub from that link
machine to a file
~/.ssh/authorized_keys on cumulus.
Unless a directory ~/.ssh already exists on
cumulus, create one by logging into
cumulus and entering the mkdir
and chmod commands above.
% ssh cumulus.cs.stolaf.edu
cumulus$ mkdir .ssh
cumulus$ chmod 700 .ssh
Now append the Link computer's public key file to the end of
the file
~/.ssh/authorized_keys on the cumulus head node.
If ~/.ssh/authorized_keys doesn't already exist on
cumulus, you can simply copy the public key
while logged into the Link computer as follows:
% scp ~/.ssh/id_rsa.pub cumulus.cs.stolaf.edu:~/.ssh/authorized_keys
If ~/.ssh/authorized_keys does already exist, you
can add the new public key to the end of that file as follows:
% scp ~/.ssh/id_rsa.pub cumulus.cs.stolaf.edu:~/.ssh/tmp
cumulus$ cd ~/.ssh
cumulus$ cat tmp >> authorized_keys
cumulus$ rm tmp
Note: The first of these commands is performed on the Link
computer, and the remaining commands are performed on the cumulus head node.
Now test the setup by logging out of cumulus and logging back into cumulus.cs.stolaf.edu
from the Link machine, using ssh. Not password
should be required.
Repeat this setup for other cluster(s). Note:
You can use the same public key for the other clusters that you
already created above for cumulus above, so
only the copying and testing steps need to be performed on the other
cluster(s).
Carry out the steps of the Beowiki page
Beowiki page Trapezoid_Tutorial in order to log into one of the
Beowulf clusters, create an MPI application trap.cpp
for
computing a trapeziodal approximation of an integral, and run that
application with n=8 processes.
Notes:
You may perform your computation on any of the cluster head
machines listed above,
unless otherwise instructed. Note that
these computers do not share a file system with each other or
with the St. Olaf file servers. Also note that they use the
bash shell by default, which works mostly like the
csh shell on the lab machines, but has some differences.
Try both the C version trap.c and the C++ version
trap.cpp (link in the Beowiki page).
These files must be compiled and run on the cluster (e.g.,
cumulus), but they can be created on a Link
computer and copied to the head node
cumulus.
On the head node (e.g., cumulus), create a directories ~/PDC and
~/PDC/lab1 for this lab's files on that head node.
It may be easiest to create the files trap.c and
trap.cpp using cut and paste from a browser on a link
machine. You can then use scp to copy the files from that
link machine to the head node, e.g.,
% scp ~/PDC/lab1/trap.c cumulus.cs.stolaf.edu:PDC/lab1
As indicated in Beowiki page Trapezoid_Tutorial, you can
submit your job to Slurm for parallel computation in the form of a shell
script, perhaps named trapjob.sh.
cumulus$ sbatch -n 4 -o trapjob.out trapjob.sh
The number 4 indicates the number of cores (on nodes selected by
Slurm) in your computation. The file trapjob.out in the
current directory will receive output from that computation.
Create a copy of that program named trap2.cpp, which
includes the following modifications.
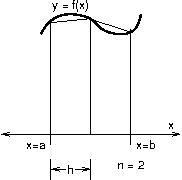
The goal of the program trap.cpp is to compute an
approximation of the integral expression
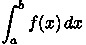 using a given number
of trapezoids.
The original
using a given number
of trapezoids.
The original trap.cpp uses 1024 trapezoids to
approximate the integral
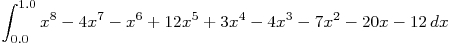 .
Modify
.
Modify trap2.cpp to compute an approximation of the
integral 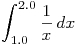 with 1048576 (= 2^20) trapezoids.
with 1048576 (= 2^20) trapezoids.
(Note: This does not require you to know calculus. Instead,
find the formula and parameters in the code and make the necessary
changes, being sure to read enough of the code to be sure you are changing the
correct values.)
You can either create trap2.cpp on the cluster
head node, or create trap2.cpp on a Link computer and
copy to the cluster head node using scp, as described
above.
Standalone vs. parallel execution. The C++ class
Trap in the program trap.cpp encapsulates the
computation necessary to approximate a definite integral in calculus
using trapezoids. Note that this class's method
approxIntegral() computes a trapezoidal approximation for
any values a, b, and n, whether or not
parallel programming is used.
Create a standalone program standalone.cpp
on a Link computer that computes
the same trapezoidal approximation of the same definite integral as in
trap2.cpp. Use the same class Trap in
standalone.cpp as you used in trap2.cpp. The
main() for
standalone.cpp needs only call the method
Trap::approxIntegral() with the (total) integral's values
a, b, n, and h and
print the results, omitting the computation involving partial sums (we are
computing everything in a single sum in this case) and omitting
mpi.h and all
MPI-related calls.
If you need to copy trap2.cpp from the head node
to your Link computer as a starting point for
standalone.cpp, you can use scp, e.g.,
% scp cumulus.cs.stolaf.edu:PDC/lab1/trap2.cpp ~/PDC/lab1
Compile and run standalone.cpp on a Link
computer using the
ordinary g++ compiler, without Slurm (which doesn't exist
on the Link machines).
% g++ -c standalone.cpp
% g++ -o standalone standalone.o
% standalone
Output from nodes. The mpirun program
that we are using to execute MPI jobs captures and merges the standard
output streams from all of the nodes (processing elements). Test this
by adding an output
statement that includes the MPI node identifier my_rank
just after each node determines its each value of
integral.
For the C++ version trap.cpp, the value of
integral is determined by the call of
Trap::approxIntegral(), and you can insert
cout << "node " << my_rank << " computed subtotal "
<< integral << endl;
For the C version trap.c, the value of
integral is determined by the call of
Trap(), and you can insert
printf("node %d computed subtotal %f\n", my_rank, integral);
Profiling. Postponed
Collective communication using Reduce().
The program trap.cpp uses MPI::COMM_WORLD
methods Send() and Recv() to communicate
from one process to another. These are examples of
point-to-point communication, in which a particular
source process sends a message to a particular
destination process, and that destination process receives
that message.
MPI also provides for collective communication, in which
an entire group of processes participates in the communication. One
example of collective communication is the MPI Bcast()
method ("broadcast"), in which one process sends a message to all
processes in an MPI communicator (such as COMM_WORLD) in
a single operation.
Broadcasting won't help with the communication needed in
trap.cpp, but a different MPI communication method called
Reduce() performs exactly the communication that
trap.cpp needs. In a Reduce() operation, all
processes in a communicator provide a value by calling the
Reduce() method, and one designated destination process
receives a combination of all those values, combined using an
operation such as addition or maximum.
Modify the program trap2.cpp to create a new version
trapR.cpp that uses collective communication via
Reduce() instead of point-to-point communication with
Send() and Recv() in order to communicate
and add up the partial sums. A single Reduce() call will
replace all the code for Sending, Recving,
and summing integral values. According to the manual
page, a method call
MPI::COMM_WORLD.Reduce() has the following
arguments (in order):
operand, the address of a variable containing the
contributed value from a process (in our case, a partial sum);
result, the address of a variable to be filled in with the
combined value (such as total in trap.cpp);
count, an int length of the variables
operand and result (enabling those variables
to be arrays)
datatype, indicating the type of the variables
operand and result (such as MPI::FLOAT
or MPI::INT);
operator, indicating the combining operation to be
performed, such as MPI::SUM, MPI::PROD, or
MPI::MAX; and
root, an int designating the rank of the
unique process that is to receive the combined operand values
in its result variable.
Note: All processes in the communicator must provide all
arguments for their Reduce() calls, even the combined
value is stored only in the root process's result
argument. MPI makes this requirement in order for the
Reduce() call to have the same format for all processes
in a communicator. A Reduce() call can be thought of
as a single call by an entire communicator, rather than individual
calls by all the processes in that communicator.
Instance vs. class methods. Observe that we never
actually create an instance of the class Trap in the
programs trap.cpp and trap2.cpp. Instead, we
call the class method approxIntegral using the
scope operator :: (Trap::approxIntegral()).
The keyword static in the definition of the method
approxIntegral indicates that it is a class method.
Note: The MPI operations Init,
Send, Receive, etc., are also implemented as
class methods, making it unnecessary to create an instance of the
class MPI.
Create a new version trap3.cpp of the trapezoid program
in which approxIntegral is an instance method
instead of a class method, as a review exercise in C++ programming.
This will require you to create an
instance trap of the class Trap and perform
the call trap.approxIntegral(...) in order to compute a
trapezoidal approximation. (To change a class method to an instance
method, remove the keyword static.) Compile
trap3.cpp for parallel computation (with
mpiCC) and test it using a Slurm job.
-
Data decomposition (parallel programming pattern).
A parallel programming pattern is an
effective, reusable strategy for designing parallel computations.
Such strategies, which have typically been discovered and honed through
years of practical experience in industry and research, can apply in
many different applied contexts and programming technologies. Patterns
act as guides for problem solving, the essential activity in
Computer Science, and they provide a way for students to gain
expertise quickly in the challenging and complex world of parallel
programming.
This lab exhibits several parallel programming patterns:
The Data Parallel pattern appears in our
approach to dividing up the basic work of the problem: to add the
areas of all the trapezoids, we break up the data so that each
processing element (e.g., core in a cluster node) carries out a
portion of the summation, and together they span the entire
summation. We will also call this the Data
decomposition pattern.
The Message Passing pattern is represented in the
point-to-point communication of MPI Send and
Receive operations used in these codes.
The reduce approach to programming the problem used in
trapR.cpp represents a Collective Communication pattern.
Data Decomposition is considered to be a higher
level pattern than the others. Higher level patterns
are closer to the application, and lower level patterns are
closer to the hardware. Observe that we referred to the applied
problem of computing areas by adding up trapezoids when describing how
Data Decomposition relates to our problem, but Message Passing and Collective Communication are more directly concerned with the
mechanics of computer network communication and of performing
arithmetic with results produced at multiple hosts.
As the program standalone.cpp indicates, the original
Trap class does not implement any of the Data
decomposition of the problem -- all the subdivision of intervals in
trap.cpp occurs in main(). In this
step of the lab, we will move the data decomposition into the class
Trap, making main() easier to write.
Start by making a copy trap4.cpp of your program
trap3.cpp. Modify the class Trap in
trap4.cpp as follows:
Add the following state variables:
nprocs, the int number of processing
elements to divide this computation among.
id, the index of a particular
processing element, which will have an int value from 0
to nprocs-1 inclusive.
Add a constructor satisfying the following spec.
Trap
Constructor
2 arguments:
np, int number of processing elementsi, int an index of a processing element
State change: Assigns the value np to the state variable
nprocs, and assigns the value i to the
state variable id
An instance of Trap will correspond to the portion
of the area computation for a single processing element to carry out.
Modify the method approxIntegral (or add a second
version of that method) to take three arguments.
approxIntegral
Method
3 arguments:
a, double lower limit of integration for the entire problemb, double upper limit of integration for the entire problemn, int number of trapezoids for the entire problem
State change: none
Return: double, this processing element's
computed portion of a trapezoidal approximation of
The code for this method should determine the
local_a, local_b, and local_n
values for a particular processing element according to the state
variables nprocs and id (note that
id would be the MPI rank), then compute that
processing element's portion of the trapezoidal approximation, and
return the result.
Finally, modify main() in trap4.cpp to use
the new class. The MPI calls will remain in main() but
the Data Decomposition involving
local_a, etc., can all
be deleted, leading to a more easily understood main program.
Compile (using mpiCC) and test
your program (using a Slurm job).
Reusability of patterns.
This same
class Trap might be used with some other form of
parallelization besides MPI. This illustrates another aspect of
patterns like Data Decomposition: these effective problem-solving strategies can be used with many
different parallel programming technologies.
This lab is due by Wednesday, January 7, 2015.