{kind=link}
In-class notes for 04/04/2014
CS 121B (CS1), Spring 2014
-
Fall CS courses
CS 241, Hardware Design [HD]. Prereq: CS 121 or 125
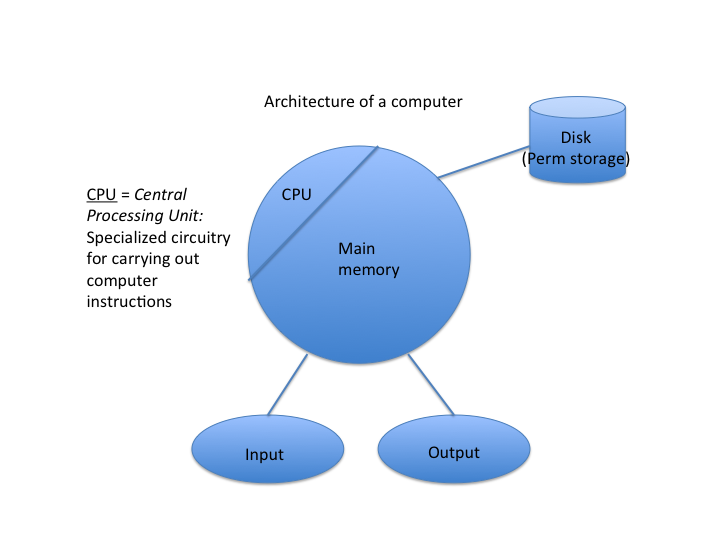
How can an electronic circuit carry out computer instructions for a language like Python3?
Design of computer hardware; connection of hardware to various programming languages; current and future trendsThis is a unique time of revolutionary change in history of computer hardware, and HD explains why.
CS 251, Software Design [SD]. Prereq: CS 121 or 125
Designing and building software using the popular C++ programming language,
plus a substantial structured team project
Includes a .25 cr lab, for more "time-on-task" mastering programming skillsWorks equally well as a last course in CS (strategic preparation for creating software relevant to other fields)
or as a next course (there's a reason why it's a prereq for almost every other CS course)
-
Next week: Science Symposium, on "Big Data"
Events Thursday evening, Friday afternoon and evening.
Friday evening speaker: Dr. Kathy Yelick, CS prof at University of California/Berkeley and lead researcher at Lawrence-Berkeley National Labs
"More Data, More Science, and... Moore's Law?"
Friday 4/11, 7:30pm, Tomson 280. Extra credit for attending sessions and writing 1-page reactions.Click here for more information and complete schedule
Submitted questions on assignments and technology
Upcoming
Submitted questions on readings
Intro to WebMapReduce
Map-reduce computing
-
Basic idea of map-reduce computing:
Break data up into labelled pieces (
mapper())Gather and combine pieces that have the same label (
reducer())
Example: For computing word frequencies, we
- break up each line
of text into words, and emit a labelled piece (key = word, value =
'1') for each word found, then - gather all the
'1's for each word, and add up those'1's as integers to determine the frequency for that word.
Stages of computation:
mapper stage: start with one line of the original data; produce intermediate key-value pairs.
shuffle stage: organize key-value pairs according to key; transmit across network to a convenient location for next stage.
reducer stage: start with all key-value pairs for a given fixed key; produce result key-value pairs of interest.
A map-reduce implementation (such as
Hadoop, which we use) takes care of details such as splitting the data and shuffling, so a map-reduce programmer needs only provide mapper and reducer algorithms.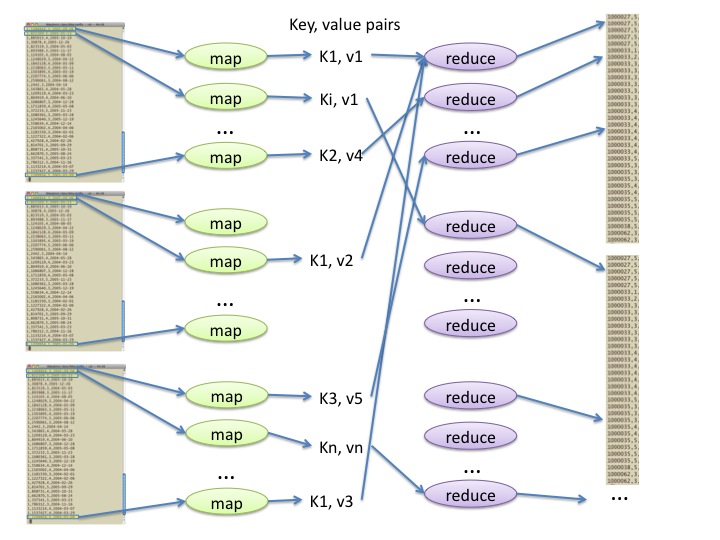
Exercises
Exercise 1:
Use WMR to compute the highest reviewer id in a netflix dataset.
HintsA sample data set:
1,1596531,5,2004-01-23 3,2318004,4,2004-02-05 6,110641,5,2003-12-15 8,1447639,4,2005-03-27 8,2557899,5,2005-04-16 6,52076,4,2004-10-05 1,13651,3,2004-06-16 1,1374216,2,2005-09-23
Spec for mapper:
# IN format # key is a netflix record value is empty string # NOTE: netflix record format is movieID,reviewerID,rating,date # OUT format # key is empty value is a reviewerID
Spec for reducer:
# IN format # key is empty value are reviewerID # OUT format # key is maximum reviewer id value is empty
Hints: (a) use
split()with an argument; (b) use an accumulator in reducer to determine the maximum value (since reviewerIDs are non-negative, you can initialize accumulator at -1); (c) use the Test interface to debug.
Exercise 2:
Compute the average ratings for all movies
You can use the same data set as above. For that data set, the results should be:
1 3.3333 3 4 6 4.5 8 4.5mapper()specs# IN format # key is a netflix record value is empty string # NOTE: netflix record format is movieID,reviewerID,rating,date # OUT format # key is a movieID value is a rating
reducer()specs# IN format # key is a movieID values are ratings # OUT format # key is a movieID value is the mean movie rating for that movie
Hints: (a) Use two accumulators in reducer, one for sum and one for count, in order to compute the mean
< >