Introduction to MPI programming
Split SPLIT_ID
CS 300, Parallel and Distributed Computing (PDC)
First submission due
9/14/2018; complete lab due 9/18/2018
This assignment is being revised and tested. Completion will be announced on Piazza
Introduction to MPI programming
trap.cpp
checksums of system files
Preliminary material
Accessing the Beowulf cluster Cumulus. Cluster head node
cumulus.cs.stolaf.edu; commandssh -XPasswordless SSH setup - discussed in class.
Note: Logging in from CS-managed network to St. Olaf network requires VPN, not currently provided on the CS-managed machines. But you can log into CS-managed machines from link machines or your laptop, but not the other way aroundTrapezoidal rule for approximating integrals (calculus)
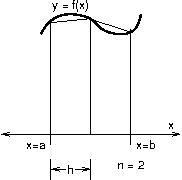
Parallel strategy for computing trapezoidal approximation, one "partial sum" per process.
Compiling and running MPI programs.
System changes...
Laboratory exercises
We assume you created a PDC directory in the first homework, and set it up for stogit. If you haven't, please complete those sections of HW1.
Create a directory within
~/PDCfor your work on this lab.% cd ~/PDC % mkdir lab1 % cd lab1
Create a directory
~/.sshon a Link machine, if you don't already have one.% mkdir ~/.ssh % chmod 700 ~/.ssh % cd ~/.ssh
Don't forget the "dot". Note: Thechmodcommand changes the Linux protection of that directory so that only your account (and therootaccount) can access it.Open a terminal window and try logging into
cumulusas follows.link% ssh username@cumulus
Whereusernameis your St. Olaf username. If this step fails, you probably don't have an account oncumulus. Contact RAB for access.Note: You can omit
username@in the command above if you are logged in asusername(e.g., if you are logged into a Link computer).
Once you have successfully logged in to
cumulus, log out from that machine.cumulus$ exit
(Don't enter the
$sign: it stands for thebashshell prompt on the head node (e.g.,cumulus.)Generate a public key and a private key for authentication.
link% ssh-keygen -t rsa -P ""
Copy the public key
id_rsa.pubfrom your link machine account to the head nodecumulus.% ssh-copy-id -i ~/.ssh/id_rsa.pub localhost
Reminder: Enter this command on a Link computer (or another computer on the St. Olaf network), not oncumulus.-
a file
~/.ssh/authorized_keysoncumulus.Unless a directory
~/.sshalready exists oncumulus, create one by logging intocumulusand entering themkdirandchmodcommands above.% ssh cumulus.cs.stolaf.edu cumulus$ mkdir .ssh cumulus$ chmod 700 .ssh
Now append the Link computer's public key file to the end of the file
~/.ssh/authorized_keyson thecumulushead node.If
~/.ssh/authorized_keysdoesn't already exist oncumulus, you can simply copy the public key while logged into the Link computer as follows:% scp ~/.ssh/id_rsa.pub cumulus.cs.stolaf.edu:~/.ssh/authorized_keys
If
~/.ssh/authorized_keysdoes already exist, you can add the new public key to the end of that file as follows:% scp ~/.ssh/id_rsa.pub cumulus.cs.stolaf.edu:~/.ssh/tmp cumulus$ cd ~/.ssh cumulus$ cat tmp >> authorized_keys cumulus$ rm tmp
Note: The first of these commands is performed on the Link computer, and the remaining commands are performed on thecumulushead node.
Now test the setup by logging out of
cumulusand logging back intocumulus.cs.stolaf.edufrom the Link machine, usingssh. Not password should be required.Repeat this setup for other cluster(s). Note: You can use the same public key for the other clusters that you already created above for
cumulusabove, so only the copying and testing steps need to be performed on the other cluster(s).
Set up stogit on your
cumulusaccount.Create an RSH SSH key pair on
cumulus. (Sincecumulusdoesn't share your IT home directory, you can't use the SSH keys you've already created for link computers.)cumulus$ ssh-keygen -t rsa
Set up public key access from
Note: You should be able to usecumulustostogitby adding yourcumuluspublic key~/.ssh/id_rsa.puboncumulusto your Profile settings onstogit.cs.stolaf.edu.cumulus$ cat ~/.ssh/id_rsa.pub
to show your public key on a terminal window logged intocumulus, then copy and paste into a browser running on a different computer (like your own computer or a link machine you're logged into).Perform these git steps while logged into the
cumulushead node:cumulus$ git config --global user.name "First Last" cumulus$ git config --global user.email "username@stolaf.edu" cumulus$ git config --global core.editor "emacs"
Now clone your stogit account for the course into a new subdirectory
PDCin yourcumulusaccount.cumulus$ cd ~ cumulus$ git clone git@stogit.cs.stolaf.edu:pdc-f18/user.git PDC
Cloning creates a new working directory for your stogit repository. You will now have (at least) two working directories, one on link computers, and one oncumulus.Note: It's especially important to
pullbefore youpushwhenever there are multiple working directories for the same git repository, so that changes made andpushedfrom one working directory can be synchronized viapullbeforepushing changes from another working directory.If you already have created files on
cumulusin a subdirectoryPDC, perform the following commands instead of cloning.cumulus$ cd ~/PDC cumulus$ git init cumulus$ git remote add origin git@stogit.cs.stolaf.edu:pdc-f18/user.git
You can nowpull/pushin order to synchronize your work with stogit.
MPI computation on Cumulus. The following steps give you an experience running an MPI computation that involves multiple processes.
Log into the
cumulus.cs.stolaf.eduhead node.The MPI program we will try is called
trap.cpp, which computes a trapezoidal approximation of an integral. This code includes MPI calls that enable multiple processes to compute part of the answer, and for a single process (the head process) to retrieve the partial answers from each other process and combine to a total answer.The MPI code in
trap.cppwas discussed in class.DO THIS: Copy
trap.cppfrom the web link above to your account on thecumulushead node using thiswgetcommand.cumulus$ wget https://www.stolaf.edu/people/rab/pdc/lab/trap.cpp .
Note: don't forget the final dot . , which represents your current directory on the cumulus head node (i.e., thelab1subdirectory).You can check that the
wgetdownload succeeded by examining the downloaded copy oftrap.cpp.emacs trap.cpp, orless trap.cpp
To compile
trap.cppas an MPI application, entercumulus$ mpiCC trap.cpp -o trap
mpiCCis similar togcc, except it includes the options needed to create a complete MPI executable.As a quick check, enter
ls -lin yourlab1subdirectory and look for an executable file namedtrap.Before we can successfully run the
trapMPI executable, make sure that passwordless SSH is set up on all the Cumulus worker nodes.Note: When logged into the cumulus head node, the worker nodes have the names
cumulus01,cumulus02, ...,cumulus09.In order to set up passwordless ssh between the head node and the worker nodes, we need
the cumulus head node's public SSH key must be added to
~/.ssh/authorized_keyson each of the worker nodes, andan entry for the head node needs to be added to
~/.ssh/known_hostsfor each worker node.
HOWEVER, your home directory for the cumulus head node is shared with all the cumulus worker nodes, using NFS (the same mechanism that allows the link machines to share your same home directory).
So, DO THIS:
cumulus$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
This adds the head's public key to it's ownauthorized_keysfile. (And hence, the worker nodes'authorized_keysfile, which are the same file through NFS sharing.)Log into each worker node in turn from the cumulus head node.
These worker nodes will prompt whether you want to trust the head node -- answer
yesto automatically add the head node to that worker'sknown_hostsfile.Don't forget to log out of the worker node (you could use the
exitshell command), which returns you to the cumulus head node for the next login.
After setting up passwordless SSH to worker nodes as above, you can run your new
trapMPI program as follows:cumulus$ mpiexec -hostfile /usr/mpihosts -np 4 ./trap
while you are in yourlab1directory. The result should be some output from each worker node, followed by an combined answer (about 34.7) printed by the head node.You may perform your computation on any of the cluster head machines listed above, unless otherwise instructed. Note that CS-managed servers such as
cumulusdo not share a file system with each other or with the St. Olaf file servers. Also, they use thebashshell by default, which works mostly like thecshshell most people use on the lab machines, but has some differences. (We will indicate thebashshell using the prompt$.)Try both the C version
trap.cand the C++ versiontrap.cpp(link in the Beowiki page).These files should be compiled and run on the cluster head node (e.g.,
cumulus), but the source code can be created on a Link computer and copied to the head nodecumulus.To create the files
trap.candtrap.cppon a Link machine, first create a~/PDC/lab1subdirectory on that link machine, and create the files in that subdirectory.link% mkdir ~/PDC/lab1 link% cd ~/PDC/lab1 link% (edit files)
You can then use git to transfer the files from that link machine to the head node as follows. On the link machine:link% git add trap.c link% git commit -m "lab1: first version of trap.c" link% git pull origin master link% git push origin master
(You couldaddandcommitbothtrap.candtrap.cppif you have already created them both.) Then, oncumulus,cumulus$ cd ~/PDC cumulus$ git pull origin master cumulus$ cd lab1
Note that thepulloperation will create a subdirectorylab1even if one doesn't exist yet. The filetrap.cshould now be available in yourPDC/lab1subdirectory oncumulus.Alternative: You could instead create the files on
cumulusinstead of a link machine.cumulus$ mkdir ~/PDC/lab1 cumulus$ cd ~/PDC/lab1 cumulus$ (edit files)
However, it may be more difficult to copy/paste code from the web code examples into an editor running oncumulus.
For this lab, use
mpirunto run your MPI program code. Example command:cumulus$ mpirun -np 4 -hostfile /usr/mpihosts trap
Here,the flag
-npindicates how many processes should participate in the computation (4 in this case),the flag
-hostfileindicates a file that lists the cluster computers to run those processes -- different processes will be assigned to different cores on those computers, when possible -- andtrapis the executable to run on the cores of those computers listed in the host file parameter.
The hostfile
/usr/mpihostsis a standard location on St. Olaf clusters for a hostfile, but you can substitute your own file if you wish.(Subject to change.) As indicated in Wiki page
Trapezoid_Tutorial, you can submit your job to Slurm for parallel computation in the form of a shell script, perhaps namedtrapjob.sh.cumulus$ sbatch -n 4 -o trapjob.out trapjob.sh
The number 4 indicates the number of cores (on nodes selected by Slurm) in your computation. The filetrapjob.outin the current directory will receive output from that computation.Create a commit containing your source file (only), if you haven't done so already.
cumulus$ git add trap.cpp cumulus$ git commit -m "lab1: first version of trap.cpp"
Even if you had already created acommitof these files (e.g., on a Link computer), be sure to create a newcommit(with an appropriatecommitmessage) if you made any changes in those files.Note: It's not necessary to
pull/pushthis newcommitat this time, if you needed to create one. (You may if you want, or wish to copy to another system via git.)
Create a copy of that program named
trap2.cpp, which includes the following modifications.The goal of the program
trap.cppis to compute an approximation of the integral expression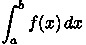 using a given number
of trapezoids.
The original
using a given number
of trapezoids.
The original trap.cppuses 1024 trapezoids to approximate the integral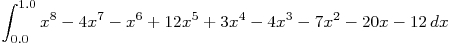 .
Modify
.
Modify trap2.cppto compute an approximation of the integral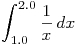 with 1048576 (= 2^20) trapezoids.
with 1048576 (= 2^20) trapezoids.
(Note: This does not require you to know calculus. Instead, find the formula and parameters in the code and make the necessary changes, being sure to read enough of the code to be sure you are changing the correct values.)
You can either create
trap2.cppon the cluster head node, or createtrap2.cppon a Link computer and copy to the cluster head node usinggit, as described above.When you're ready, create a
commitcontaining working code fortrap2.cpp, if you haven't done so already.cumulus$ git add trap2.cpp cumulus$ git commit -m "lab1: added trap2.cpp"
Standalone vs. parallel execution. The C++ class
Trapin the programtrap.cppencapsulates the computation necessary to approximate a definite integral in calculus using trapezoids. Note that this class's methodapproxIntegral()computes a trapezoidal approximation for any valuesa, b,andn, whether or not parallel programming is used.Create a standalone program
standalone.cppon a Link computer that computes the same trapezoidal approximation of the same definite integral as intrap2.cpp. Use the same classTrapinstandalone.cppas you used intrap2.cpp. Themain()forstandalone.cppneeds only call the methodTrap::approxIntegral()with the (total) integral's valuesa, b, n,andhand print the results, omitting the computation involving partial sums (we are computing everything in a single sum in this case) and omittingmpi.hand all MPI-related calls.If you need to copy
trap2.cppfrom the head node to your Link computer as a starting point forstandalone.cpp, you can usescp, e.g.,% scp cumulus.cs.stolaf.edu:PDC/lab1/trap2.cpp ~/PDC/lab1
Compile and run
standalone.cppon a Link computer using the ordinaryg++compiler.% g++ -c standalone.cpp % g++ -o standalone standalone.o % standalone
- When you know you have working code, create a
commitcontaining it.cumulus$ git add standalone.cpp cumulus$ git commit -m "lab1: standalone.cpp"
Output from nodes. The
mpirunprogram that we are using to execute MPI jobs captures and merges the standard output streams from all of the nodes (processing elements). Test this by adding an output statement that includes the MPI node identifiermy_rankjust after each node determines its each value ofintegral.For the C++ version
trap.cpp, the value ofintegralis determined by the call ofTrap::approxIntegral(), and you can insertcout << "node " << my_rank << " computed subtotal " << integral << endl;For the C version
trap.c, the value ofintegralis determined by the call ofTrap(), and you can insertprintf("node %d computed subtotal %f\n", my_rank, integral);Create a
commitcontaining whichever version(s) you modified, with a helpfulcommitmessage. For example,cumulus$ git add trap.cpp cumulus$ git commit -m "lab1: trap.cpp with output from processes"
End of first submission stage.
Submit your work up to this step (or later) by Friday, September 14, 2018 as follows:
cumulus$ git pull origin master cumulus$ git push origin master
Profiling. Postponed
Collective communication using
MPI_Reduce(). The programtrap.cppuses library functionsMPI_Send()andMPI_Recv()to communicate from one process to another. These are examples of point-to-point communication, in which a particular source process sends a message to a particular destination process, and that destination process receives that message.MPI also provides for collective communication, in which an entire group of processes participates in the communication. One example of collective communication is the
MPI_Bcast()call ("broadcast"), in which one process sends a message to all processes in an MPI communicator (such asMPI_COMM_WORLD) in a single operation.Broadcasting won't help with the communication needed in
trap.cpp, but a different MPI communication function calledMPI_Reduce()performs exactly the communication thattrap.cppneeds. In aMPI_Reduce()operation, all processes in a communicator provide a value by calling theMPI_Reduce()library function, and one designated destination process receives a combination of all those values, combined using an operation such as addition or maximum.Modify the program
trap2.cppto create a new versiontrapR.cppthat uses collective communication viaMPI_Reduce()instead of point-to-point communication withMPI_Send()andMPI_Recv()in order to communicate and add up the partial sums. A singleMPI_Reduce()call will replace all the code forMPI_Sending,MPI_Recving, and summingintegralvalues. According to the manual page, a library callMPI_Reduce()has the following arguments (in order):operand, the address of a variable containing the contributed value from a process (in our case, a partial sum);
result, the address of a variable to be filled in with the combined value (such as
totalintrap.cpp);count, an
intlength of the variables operand and result (enabling those variables to be arrays)datatype, indicating the type of the variables operand and result (such as
MPI_FLOATorMPI_INT);operator, indicating the combining operation to be performed, such as
MPI_SUM,MPI_PROD, orMPI_MAX;root, an
intdesignating the rank of the unique process that is to receive the combined operand values in itsresultvariable; andcomm, an MPI communicator, i.e., a group of MPI processes (we will choose the default
MPI_COMM_WORLD.
Note: All processes in the communicator must provide all arguments for their
MPI_Reduce()calls, even the combined value is stored only in the root process's result argument. MPI makes this requirement in order for theMPI_Reduce()call to have the same format for all processes in a communicator. AMPI_Reduce()call can be thought of as a single call by an entire communicator, rather than individual calls by all the processes in that communicator.Create a
commitcontaining your programtrapR.cppcumulus$ git add trapR.cpp cumulus$ git commit -m "lab1: trapR.cpp, using MPI_Reduce"
Instance vs. class methods. Observe that we never actually create an instance of the class
Trapin the programstrap.cppandtrap2.cpp. Instead, we call the class methodapproxIntegralusing the scope operator::(Trap::approxIntegral()). The keywordstaticin the definition of the methodapproxIntegralindicates that it is a class method.Note: The MPI operations
Init,Send,Receive, etc., are also implemented as class methods, making it unnecessary to create an instance of the classMPI.Create a new version
trap3.cppof the trapezoid program in whichapproxIntegralis an instance method instead of a class method, as a review exercise in C++ programming. This will require you to create an instancetrapof the classTrapand perform the calltrap.approxIntegral(...)in order to compute a trapezoidal approximation. (To change a class method to an instance method, remove the keywordstatic.) Compiletrap3.cppfor parallel computation (withmpiCC) and test it.When you know you have working code, create a
commitcontaining it.cumulus$ git add trap3.cpp cumulus$ git commit -m "lab1: trap3.cpp, instance methods instead of class methods"
-
Data decomposition (parallel programming pattern).
A parallel programming pattern is an effective, reusable strategy for designing parallel and distributd computations. Such strategies, which have typically been discovered and honed through years of practical experience in industry and research, can apply in many different applied contexts and programming technologies. Patterns act as guides for problem solving, the essential activity in Computer Science, and they provide a way for students to gain expertise quickly in the challenging and complex world of parallel programming.
This lab exhibits several parallel programming patterns:
The Data Parallel pattern appears in our approach to dividing up the basic work of the problem: to add the areas of all the trapezoids, we break up the data so that each processing element (e.g., core in a cluster node) carries out a portion of the summation, and together they span the entire summation. We will also call this the Data decomposition pattern.
The Message Passing pattern is represented in the point-to-point communication of MPI
SendandReceiveoperations used in these codes.The reduce approach to programming the problem used in
trapR.cpprepresents a Collective Communication pattern.The Loop Parallel pattern focuses on computationally intensive loops as opportunities for parallelism.
Data Decomposition is considered to be a higher level pattern than the others. Higher level patterns are closer to the application, and lower level patterns are closer to the hardware. Observe that we referred to the applied problem of computing areas by adding up trapezoids when describing how Data Decomposition relates to our problem, but Message Passing and Collective Communication are more directly concerned with the mechanics of computer network communication and of performing arithmetic with results produced at multiple hosts.
The Loop Parallel pattern is at a "mid-level," not as high (i.e., not as close to the application) as Data Decomposition, but not as low (close to the hardware) as Message Passing or Collective Communication.
As the program
standalone.cppindicates, the originalTrapclass does not implement any of the Data decomposition of the problem -- all the subdivision of intervals intrap.cppoccurs inmain(). In this step of the lab, we will move the data decomposition into the classTrap, makingmain()easier to write.Start by making a copy
trap4.cppof your programtrap3.cpp. Modify the classTrapintrap4.cppas follows:Add the following state variables:
nprocs, theintnumber of processing elements to divide this computation among.id, the index of a particular processing element, which will have anintvalue from 0 tonprocs-1 inclusive.
Add a constructor satisfying the following spec.
Trap
Constructor
2 arguments:
np,intnumber of processing elementsi,intan index of a processing element
State change: Assigns the value
npto the state variablenprocs, and assigns the valueito the state variableidAn instance of
Trapwill correspond to the portion of the area computation for a single processing element to carry out.Modify the method
approxIntegral(or add a second version of that method) to take three arguments.approxIntegral
Method
3 arguments:
a,doublelower limit of integration for the entire problemb,doubleupper limit of integration for the entire problemn,intnumber of trapezoids for the entire problem
State change: none
Return:
double, this processing element's computed portion of a trapezoidal approximation ofThe code for this method should determine the
local_a,local_b, andlocal_nvalues for a particular processing element according to the state variablesnprocsandid(note thatidwould be the MPI rank), then compute that processing element's portion of the trapezoidal approximation, and return the result.
Finally, modify
main()intrap4.cppto use the new class. The MPI calls will remain inmain()but the Data Decomposition involvinglocal_a, etc., can all be deleted, leading to a more easily understood main program.Compile (using
mpiCC) and test your MPI program.When you know you have working code, create a
commitcontaining it.cumulus$ git add trap4.cpp cumulus$ git commit -m "lab1: trap4.cpp, data decomposition within class Trap"
Reusability of patterns.
This same class
Trapmight be used with some other form of parallelization besides MPI. This illustrates another aspect of patterns like Data Decomposition: these effective problem-solving strategies can be used with many different parallel programming technologies.
Notes:
Deliverables
To submit your work, you need git set up on the on the cluster head node(s) you used, as described above.
All of your code for this assignment should already be contained in
commits. Modify the most recentcommitmessage to indicate that you are submitting the completed assignment.cumulus$ git commit --amend
Add the following to the latestcommitmessage.lab1: completeIf your assignment is not complete, indicate your progress instead, e.g.,lab1: items 1-5 complete, item 6 partialYou can make later commits to submit updates.Finally,
pull/pushyourcommits in the usual way.cumulus$ git pull origin master cumulus$ git push origin master
Now that you have
gitset up on all the computers you used, you have two options for how to submit your work on this lab.The simpler approach is to rename your subdirectories according to which computer the work is located on. For example,
% cd ~/PDC % mv lab1 lab1-link cumulus$ cd ~/PDC cumulus$ mv lab1 lab1-cumulus
After these renamings, perform the following instructions on all hosts you used for the assignment:% cd ~/PDC % git pull origin master % git add -A % git commit -m "lab1 submit on link" % git push origin master cumulus$ cd ~/PDC cumulus$ git pull origin master cumulus$ git add -A cumulus$ git commit -m "lab1 submit on cumulus" cumulus$ git push origin master
If you use this approach, be sure it is clear which versions of files are the current ones. For example, in this lab, there may be versions oftrap.con both the Link andcumulus; which one is final, or are they both the same. One way to record this is to delete old versions, or copy them to a sub-subdirectory namedold. Or, you could create text files namedREADME.txtin each appropriate lab1 directory to indicate the status of your files.If you prefer to store all of your files in one
lab1directory, here is an alternative approach to submitting.We will use
git's branch feature for this approach, which support multiple lines of development in a singlegitproject, because ______ (details to follow)
Also, fill out this form to report on your work. (Optional in 2015.)
The final submission of this lab is due by 9/18/2018.
Files: trap.c trap.cpp trap2.cpp standalone.cpp trap.cpp trapR.cpp trap3.cpp trap4.cpp